Visualisering av beskrivande statistik
Stapeldiagram
Den absolut enklaste formen av visualisering är stapeldiagram. Denna diagramtyp består utav staplar vars höjd kommer från ett värde i datamaterialet, vanligtvis då man har en kvalitativ variabel och dess frekvenser (antalet av de olika arterna i diagrammen från tidigare kapitel), men diagramtypen kan också användas då man har en kvantitativ variabel uppdelad på en eller flera kvalitativa variabler (medellönen uppdelat på olika sektorer). Följande exempel kommer utgå från det första fallet.
Olika programvaror kräver olika mycket bearbetning av datamaterialet innan diagrammet kan skapas. Vissa kräver att du själv skapar en frekvenstabell och anger att höjden av respektive stapel ska bestämmas av den tillhörande frekvensen, medan andra kan göra dessa beräkningar direkt på rådata.
Som tidigare nämnt om R använder sig programmet av diverse paket som innehåller redan skapade funktioner för att lösa diverse arbetsuppgifter. För visualisering kommer vi använda oss främst av paketet ggplot2 som bygger på vad som kallas för
grammar of graphics. Detta är ett försök till att formalisera ett språk för hur man enhetligt bör “skriva” visualiseringar och även SPSS använder sig av grunderna till detta språk. Det första steget för att få ta del av funktionerna är att ladda paketet till din R-session genom:
require(ggplot2)
Paketets visualiseringar utgår ifrån en data.frame vilket innebär att vi behöver ladda in ett datamaterial innan vi kan påbörja visualiseringarna. Detta kan göras med någon utav funktionerna read.csv(), read.csv2() osv. Se till att datamaterialet som laddats in ser ut som vi förväntar att det ska göra, exempelvis att decimalerna är korrekt angivna, att vi har lika många variabler i R som i Excel, och liknande. Med koden nedan kan datamaterialet (länk för nedladdning) som används som exempel genom hela detta material laddas in i R till objektet som kallas exempeldata. Vi kan även se hur materialet ser ut genom att använda head() som skriver ut ett antal observationer. Materialet ser ut att innehålla fem variabler, varav två (civilstånd och bil) är kvalitativa.
exempeldata <- read.csv2(file = "data_sets/732G45_exempeldata.csv")
head(exempeldata, n = 5)
## civilstand alder bil syskon lon
## 1 Par 26 Opel 0 26793
## 2 Par 44 Ford 2 49588
## 3 Par 34 Volvo 3 40461
## 4 Par 33 Ingen 4 40299
## 5 Par 32 Audi 3 36942
Grundkomponenter
Vi kan nu börja med att skapa stapeldiagrammet. Vi börjar med de tre grundkomponenterna av ett ggplot-diagram; ggplot(), aes() och geom(). Alla diagram måste innehålla dessa tre komponenter i någon form för att vi ska kunna producera något överhuvudtaget, sen kan vi lägga till andra instruktioner för att ändra diagrammets utseende.
Med ggplot() anges vilket datamaterial vi vill använda för visualiseringen:
ggplot(exempeldata)

Som vi ser skapas inget utifrån detta kommando, vi har bara sagt åt R att använda datamaterialet men inte vad den ska göra med det. Nästa steg är att ange vilka variabler vi vill använda för axlarna i diagrammet. När det kommer till stapeldiagram kan vi skapa diagrammet på två olika sätt; antingen har vi rådata och låter R räkna ut frekvensen av de olika kategorierna själv eller så har vi sammanställd data i en frekvenstabell och anger frekvensen som höjden genom argumentet: y = frekvens. Vi kommer först börja med att skapa diagrammet utifrån rådata:
ggplot(exempeldata) + aes(x = bil)

Nu ser vi att R ritat ut de olika bilarna som finns i materialet på x-axeln, men vi har fortfarande inte sagt åt R vad vi vill att den ska göra med informationen som ska visualiseras. Den sista grundkomponenten är den som styr vilken diagramtyp vi skapar och i ggplot2 finns många olika som vi kommer stöta på i detta material. För ett stapeldiagram anger vi geom_bar() från engelska termen bar chart.
ggplot(exempeldata) + aes(x = bil) + geom_bar()

För att y-axeln ska visa relativa frekvenser istället för absoluta, kan vi i geom_bar() lägga till koden aes(y = stat(count/sum(count))) som beräknar värden utifrån antalet (count) dividerat med summan av alla antal. Diagrammet ändrar sig inte i sin form, staplarna är fortfarande lika höga i relation till varandra, men tolkningar av detta diagram kan nu göras i andelar (procent) istället för antal.
ggplot(exempeldata) + aes(x = bil) + geom_bar(aes(y = stat(count/sum(count))))

Med dessa grundkomponenter får vi fram ett diagram, men vi kan väl alla hålla med om att det i detta läge inte ser särskilt snyggt och tydligt ut. Ett snabbt och enkelt sätt att få till lite snyggare diagram är att använda någon utav ggplot2s teman som finns tillgängliga genom olika theme_x(). Exempelvis är ett stilrent tema att utgå ifrån theme_bw() likt:
ggplot(exempeldata) + aes(x = bil) + geom_bar(aes(y = stat(count/sum(count)))) + theme_bw()

Det är nu den största funktionaliteten med ggplot2 kommer in. Vi kan spara instruktionerna vi gett åt R för att skapa diagrammet ovan och senare lägga till fler instruktioner med andra funktioner genom att använda +, på samma sätt som koderna ovan är skrivna. Vi sparar därför de nuvarande instruktionerna i ett objekt som vi kallar för p (vi kan döpa denna till vad som helst) likt:
p <- ggplot(exempeldata) + aes(x = bil) + geom_bar(aes(y = stat(count/sum(count)))) + theme_bw()
Nu ligger alla instruktioner för hur R ska rita upp diagrammet sparat i p men för att R också ska rita diagrammet måste vi också ange det för programmet likt:
p

Vi kan nu lägga till ytterligare funktioner exempelvis:
p + coord_flip()

eller:
p + scale_y_continuous(labels = scales::percent)

Notera att diagrammet inte roterades i det andra diagrammet när vi ändrade hur skalvärdena på y-axeln ser ut. Eftersom att vi inte sparar de tillagda instruktionerna någonstans kommer förändringarna endast påverka det diagram som vi tidigare kallat p. För att R ska spara dessa nya instruktioner tillsammans med grundkomponenterna vi angivit innan, måste vi spara ovanstående kod till ett objekt:
p <- p + scale_y_continuous(labels = scales::percent)
p

Denna kod sparar de nya instruktionerna tillsammans med de första grundkomponenterna i samma objekt, p, och skriver över de tidigare.
Sammanställd data
Om vi istället för rådata har sammanställd data, exempelvis i form utav en frekvenstabell, kan vi ändå skapa samma ovanstående diagram. Vi tänker oss att rådata om bilarna istället för de 64 observationerna är presenterad i följande tabell:
| Märke | Frekvens |
|---|---|
| Audi | 11 |
| Ford | 9 |
| Ingen | 5 |
| Nissan | 10 |
| Opel | 4 |
| Toyota | 5 |
| Volkswagen | 6 |
| Volvo | 14 |
Det som är viktigt är att vi fortfarande i R hanterar denna frekvenstabell som en data.frame, då ggplot kräver formatet för sina visualiseringar. Datamaterialet ser då istället ut som:
head(exempeltabell)
## Märke Frekvens
## 1 Audi 11
## 2 Ford 9
## 3 Ingen 5
## 4 Nissan 10
## 5 Opel 4
## 6 Toyota 5
För att skapa diagrammet som vi sett tidigare måste vi lägga till några argument i aes() och geom_bar() likt koden nedan. Argumentet stat = "identity" i geom_bar() krävs för att R ska räkna värdet på den angivna y-variabeln som höjden på stapeln.
ggplot(exempeltabell) + aes(x = Märke, y = Frekvens) + geom_bar(stat = "identity") + theme_bw()

Färger
Om vi vill ändra färgen på olika delar av diagrammet exempelvis staplarna kan vi göra detta inuti geom_bar() med argumenten color för kantlinjerna och fill för fyllnadsfärgen. För att se vilka färger som går att ange kan man köra funktionen colors() för deras namn eller hämta hem följande
PDF som har färgerna utskrivna. Vi kommer senare titta närmare på färger och dess funktion i visualiseringar.
p <- ggplot(exempeldata) + aes(x = bil) +
geom_bar(fill = "dark orange",
color = "black",
aes(y = stat(count/sum(count)))) +
theme_bw()
p

Stödlinjer
Nu vill vi ändra lite stödlinjer så att de syns och hjälper till att förtydliga informationen vi vill visa. När det kommer till stapeldiagram behövs inte stödlinjer på x-axeln då staplarna sträcker sig hela vägen ner till dess skalvärden. Däremot behöver vi förtydliga skalvärdena på y-axeln. För att ändra utseendet på olika delar i ett diagram används theme() och diverse olika argument däri. Titta i dokumentationen för funktionen för att få en inblick i vad som kan ändras i diagrammet. Oftast ska dessa delar anges med en utav element-funktioner, beroende på typen som ska ändras. Text ändras med element_text(), linjer med element_line() och delar kan helt och hållet tas bort genom element_blank(). Nedanstående kod ändrar stödlinjerna på y-axelns färg till lite mörkare grå än standardvärdet (panel.grid.major för stödlinjerna som följer skalvärdena, panel.grid.minor för stödlinjer emellan skalvärdena) och tar bort stödlinjerna från x-axeln.
p <- p + theme(panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_line(color = "gray70"),
panel.grid.minor.y = element_line(color = "gray80"))
p

Text
Det som saknas just nu i diagrammet är tydligare (och större) text som förklarar de olika delarna av diagrammet för läsaren. De olika etiketterna kan alla anges i samma funktion genom olika argument likt:
p <- p + labs(x = "Bilmärke", y = "Andel", caption = "Källa: Hietala (2019)")
p

Det vi kan förhålla oss till när vi anger titeln för y-axeln är att den beskriver enheten som används för att mäta axelns skalvärden. Då vi i detta fall har värden mellan \(0\) och \(1\) bör vi ange Andel som titel. Om vi skulle haft absoulta frekvenser skulle en lämplig titel varit Antal. Om vi istället för andelar anger skalan i procent likt tidigare diagram kan det diskuteras huruvida det behövs en y-axeltitel eftersom enheten redan är angiven på skalan. Diagrammet skulle då kunna se ut som:
p + scale_y_continuous(labels = scales::percent) + labs(y = "")

Vi kan även ändra andra aspekter av textens utseende i diagrammet, exempelvis hur stor den är, dess rotation eller position. Detta görs med olika argument i theme(). Vi kan ändra utseendet på axeltexter med axis.title, skalvärden med axis.text och källhänvisningen med plot.caption. Alla dessa delar kräver instruktioner från element_text()-funktionen och där kan argument som:
anglestyra rotationen,hjustochvjuststyra placeringen horisontellt respektive vertikalt,sizestyra textstorleken,fontstyra typsnittet,faceange en eventuell fet- eller kursivmarkering av texten
p <- p + theme(plot.caption = element_text(face = "italic"),
axis.title.y = element_text(angle = 0, vjust = 0.5, size = 11),
axis.title.x = element_text(size = 11),
axis.text = element_text(size = 10, color = "black"))
p

Skalvärden
Ibland kan de automatiskt genererade axelskalorna medföra svårigheter att utläsa informationen som vi ska presentera. Därför är det sista vi kommer titta på funktioner för att ändra dessa skalor. Vilken funktion vi vill använda och hur man kan ändra utseendet påverkas av vilken sorts variabel som anges på den specifika axeln. Exempelvis kanske vi vill i diagrammet ändra så att den kontinuerliga y-axeln endast visar skalvärden var 10:e procent istället för var 5:e som nu sker. Detta gör vi då via:
p + scale_y_continuous(breaks = seq(from = 0, to = 1, by = .10))

Argumentet breaks = seq(from = 0, to = 1, by = .10) anger att vi vill att värden (breaks) ska visas på specifika ställen på axeln. seq()-funktionen är ett snabbare sätt att skapa en vektor med lika steglängd mellan värden som vi använder för att skapa c(0, 0.1, 0.2, 0.3, ..., 1). Notera att trots att vi anger värden som går hela vägen upp till 1, kommer inte diagrammet visa detta.
Om vi skulle vilja visa en större del av axeln kan vi ange skalans gränser med limits likt koden nedan. Risken med detta är att vi skapar för mycket onödig tom rityta som minskar utrymmet för den information som vi vill presentera.
p + scale_y_continuous(breaks = seq(from = 0, to = 1, by = .10),
limits = c(0, 0.35))

Något som dock är snyggt att göra med specifikt stapeldiagram är att ta bort den lilla yta som finns under alla staplar och låta y-axeln möta x-axeln vid y = 0. Detta kan vi göra med argumentet expand = c(0,0), men då måste vi ange gränserna på skalan.
p <- p + scale_y_continuous(breaks = seq(from = 0, to = 1, by = .10),
limits = c(0, 0.25),
expand = c(0,0))
p

Grupperat stapeldiagram
Om vi har ett datamaterial bestående av flera kvalitativa variabler kan vi ibland vilja visualisera fördelningen av en variabel grupperat på en annan, exempelvis “Hur ser fördelningen av bilmärken ut, uppdelat på civilstånd?”. Det kanske finns några intressanta relationer mellan dessa två variabler som vi skulle vilja undersöka vidare, men som tidigare sagt är visualisering alltid det första steget för att lära känna sitt datamaterial.
I vårt exempeldata har vi två kvalitativa variabler, civilstand och bil. För att visualisera ett grupperat stapeldiagram behöver vi välja en grupperings- och en fördelningsvariabel. Fördelninsgsvariabeln kommer grupperas över varje enskilda kategori från grupperingsvariabeln.
I R måste vi ange grupperingsvariabeln likt det vi gjort tidigare som x och fördelningsvariabeln som fill inuti aes(). Detta kommer säga åt R att vardera värde på bil ska ha olika fyllnadsfärger. position = "dodge" bestämmer att staplarna ska ligga bredvid varandra och position = "stack" staplar de ovanpå varandra för ett s.k. stackat stapeldiagram.
p <- ggplot(exempeldata) +
aes(x = civilstand, fill = bil) +
geom_bar(position = "dodge") +
theme_bw()
p

För relativa frekvenser i ett grupperat stapeldiagram kan vi summera de visualiserade staplarna på två olika sätt.
- Antingen visar vi relativa frekvenser utifrån hela datamaterialet. Detta diagram kommer se exakt likadan ut som den med absoluta frekvenser men med andelar istället för antal. Vi använder samma kod som för det enkla stapeldiagrammet:
aes(y = stat(count/sum(count))).
ggplot(exempeldata) + aes(x = civilstand, fill = bil) +
geom_bar(aes(y = stat(count/sum(count))),
position = "dodge") +
theme_bw()
- Alternativet är att visa den relativa fördelningen grupperat på grupperingsvariabeln, alltså att vardera kategoris staplar summerar var för sig till 100 procent. Vi behöver då revidera koden som anger beräkningen till relativa frekvenser till:
aes(y = stat(count/tapply(count, x, sum)[x])).
ggplot(exempeldata) + aes(x = civilstand, fill = bil) +
geom_bar(aes(y = stat(count/tapply(count, x, sum)[x])),
position = "dodge") +
theme_bw()
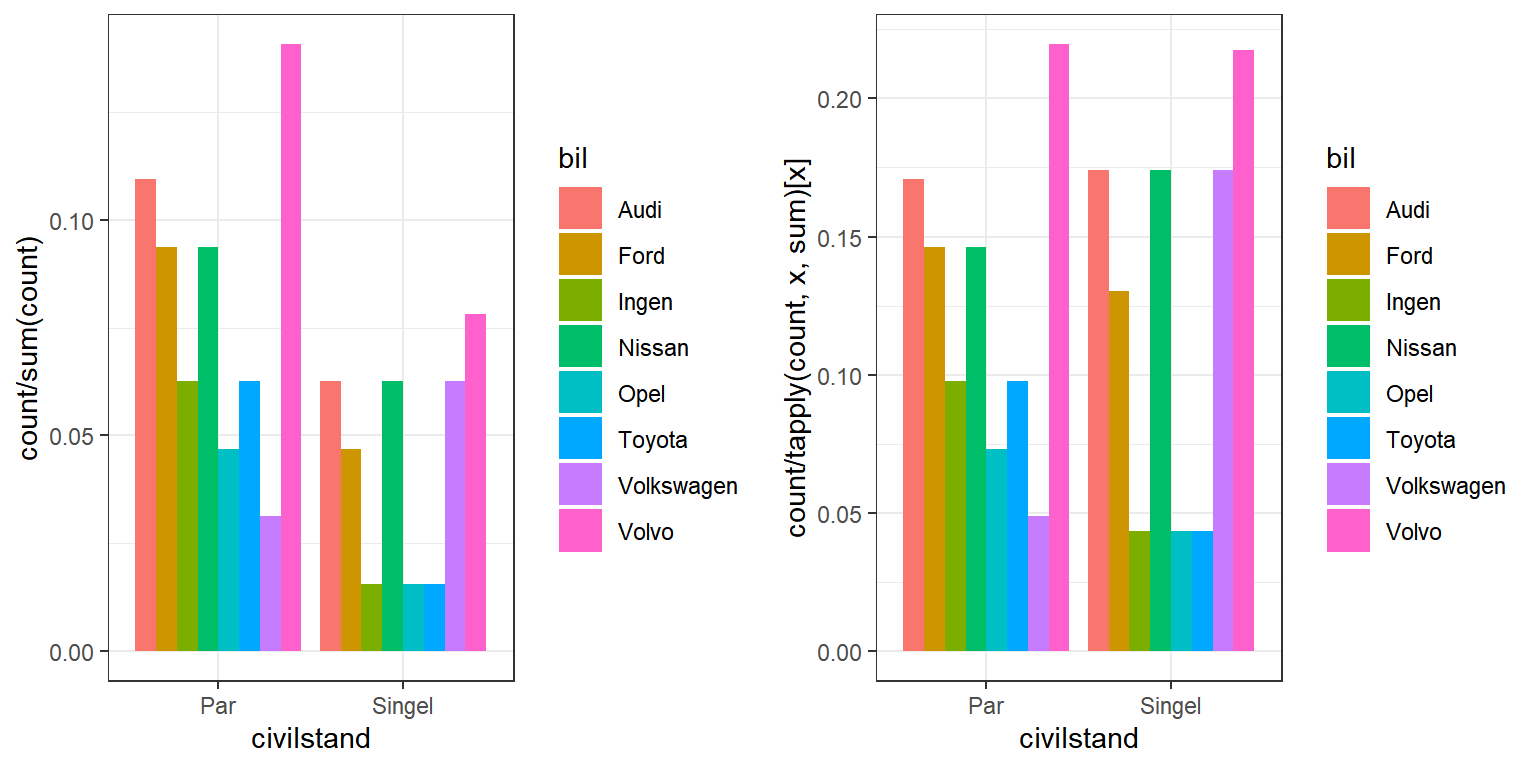
1: Figur 1: Grupperat stapeldiagram med enkel summering (t.vä.) och gruppvis summering (t.hö.) till 100 procent
Tolkningarna på vardera av dessa diagram skiljer sig åt och valet styrs av vilken sorts frågeställning som vi vill besvara med visualiseringen. En jämförelse av gruppernas fördelning skulle bli tydlig med en gruppvis summering, medan presentation av fördelningen i materialet kan visualiseras med den enkla summeringen.
Förtydliga diagrammet
Oavsett vilket sätt att summera staplarna som används ser de inte alls tydliga ut. Vi förtydligar till diagrammet med liknande hjälpfunktioner som tidigare stapeldiagram. Vi lägger till tydligare kantlinjer på staplarna, lägger till stödlinjer och etiketter, samt justerar utseendet på diverse texter samt ändrar skalan för y-axeln.
p <- ggplot(exempeldata) +
aes(x = civilstand,
fill = bil) +
geom_bar(aes(y = stat(count/sum(count))),
position = "dodge",
color = "black") +
theme_bw() +
theme(panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_line(color = "gray70"),
panel.grid.minor.y = element_line(color = "gray80"),
plot.caption = element_text(face = "italic"),
axis.title.y = element_text(angle = 0, vjust = 0.5, size = 11),
axis.title.x = element_text(size = 11),
axis.text = element_text(size = 10, color = "black")) +
labs(x = "Civilstånd",
y = "Andel",
caption = "Källa: Hietala (2019)") +
scale_y_continuous(expand = c(0,0),
breaks = seq(0, 0.20, by = 0.05),
limits = c(0, 0.16))
p

Färger
Det som också urskiljer ett grupperat stapeldiagram med det skapades tidigare är att vi nu har en legend till höger av diagramytan som innehåller ytterligare information som krävs för att läsa av diagrammet. Vi har fått olika färger på den valda fördelningsvariabeln som kopplas samman till de olika kategorierna. Dessa vill vi nu ändra tillsammans med att ändra lite information i legenden för att göra den tydligare.
För att skapa ett diagram som har en enhetlig och tydlig färgpalett kommer paketet RColorBrewer till användning. Ladda paketet med require(RColorBrewer) och titta på de olika färgkategorierna som finns att använda genom display.brewer.all(). Det rekommenderas att välja någon av de monokromatiska färgskalorna likt "Oranges" eller "Purples".
För att revidera utseendet på legenden och de använda färgerna används funktionen scale_X_manual() där X ersätts med den sorts gruppering som har gjorts för att skapa legenden, i detta fall fill. I values anges vilka färger som ska användas i diagrammet och där vill vi då använda någon palett från RColorBrewer genom brewer.pal()-funktionen. Argumentet n anger hur många färger vi vill ha och name anger vilker palett vi vill ta färgerna från.
p <- p + scale_fill_manual(name = "Bilmärke",
values = brewer.pal(n = 8,
name = "Oranges"))
p

Histogram
Om variabeln istället är kvantitativ och vi vill presentera fördelningen av denna variabel, är histogram (eller lådagram) lämpligt att använda.
Likt tidigare diagram i R behöver vi först ange vilket datamaterial samt vilken variabel som vi ska visualisera.
p <- ggplot(exempeldata) + aes(alder)
När väl det är gjort måste vi på samma sätt som tidigare ange vilken form av visualisering som ska göras. För histogram använder vi geom_histogram(), med argumentet bin som styr hur många klassintervall vi vill ha. Om vi istället vill ange hur breda intervallen ska vara kan vi använda argumentet binwidth.
p <- p + geom_histogram(fill = "orange",
color = "black",
bins = 10)
p

Vi kan också snygga till diagrammet med alla funktioner som vi tidigare använt för stapeldiagram.
p <- p + scale_y_continuous(expand = c(0,0), limits = c(0, 20)) +
theme_bw() + theme(axis.title.y =
element_text(angle = 0,
hjust = 1,
vjust = 0.5),
plot.title =
element_text(hjust = 0.5),
panel.grid.major.x =
element_blank(),
panel.grid.minor.x =
element_blank(),
panel.grid.major.y =
element_line(color = "dark gray")) +
labs(y = "Antal",
x = "Ålder",
title = "Fördelning av ålder",
caption = "Källa: Hietala (2019)")
p

Lådagram
Ett alternativ att presentera fördelningen för en kvantitativ variabel är lådagram. Denna visualiseringstyp lämpar sig bättre om det finns extremvärden i materialet då diagrammet utgår ifrån kvartiler.
Vi börjar strukturera ett lådagram på samma sätt som vi gjorde med histogrammet, dock behöver vi använda ett knep för att R ska skapa ett snyggt diagram. I aes() måste x = factor(0) som är ett sätt för R att skapa en tom kategorisk variabel. Lådagrammet skapas med geom_boxplot().
För att ta bort onödiga skalvärden och axelförklaring för den tomma variabeln som vi skapat används värdet NULL på de argument som vi vill ta bort, exempelvis breaks i scale_x_discrete().
p <- ggplot(exempeldata) + aes(x = factor(0), y = alder) +
geom_boxplot(fill = "orange") +
scale_x_discrete(breaks = NULL)
p

Snyggar till diagrammet som tidigare.
p <- p + theme_bw() + theme(axis.title.y =
element_text(angle = 0,
hjust = 1,
vjust = 0.5),
plot.title =
element_text(hjust = 0.5),
panel.grid.major.x =
element_blank(),
panel.grid.minor.x =
element_blank(),
panel.grid.major.y =
element_line(color = "dark gray")) +
labs(y = "Ålder",
x = NULL,
title = "Fördelning av ålder",
caption = "Källa: Hietala (2019)")
p
